Archeologische big data
[Datablog]
We hebben het tot nu toe gehad over de de archeologische objecten en de 3D foto’s, maar er is nog een derde interessante databron: documentatie. Dit is een hele veelzijdige en een hele grote databron. In totaal gaat dit om enkele tienduizenden stukken variërend van foto’s, opgravingstekeningen, dagrapporten tot onderzoeksrapporten. Helaas kunnen we niet alles openbaar maken vanwege auteursrechtelijke zaken. Daarnaast is van een deel van de data nu niet met zekerheid te zeggen bij welke opgraving het hoort.
Het deel dat we nu beschikbaar stellen gaat over de oudere gedigitaliseerde data waarvan bij ons bekend is bij welke opgraving het hoort. In totaal is dit zo’n 100 GB aan data.
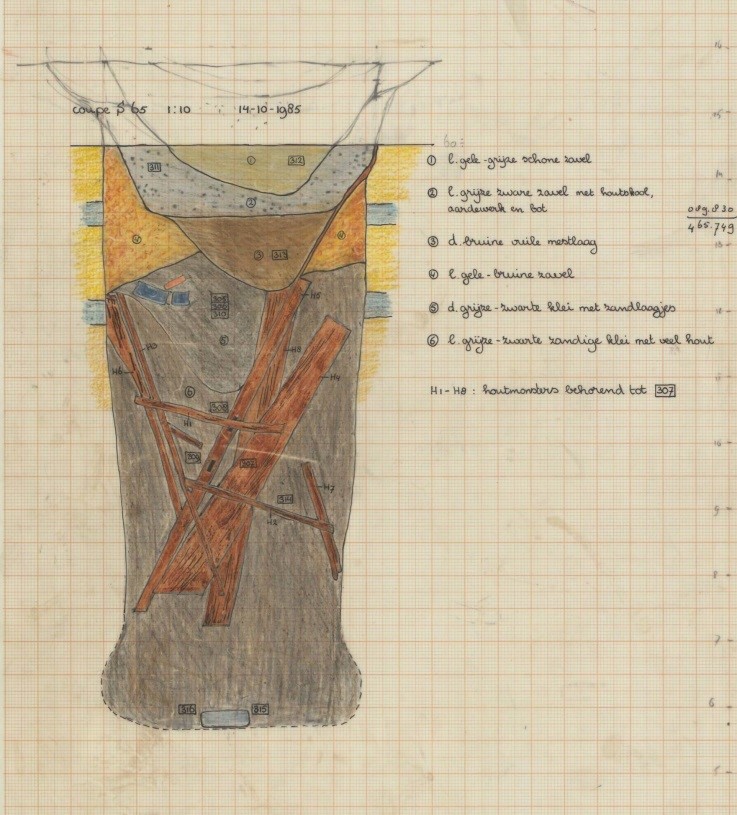
Veldtekeningen
Een van de type documenten zijn veldtekeningen. Dit zijn situatieschetsen waar vaak dwarsdoorsnedes op staan om aan te geven hoe de bodem er uit zag, inclusief de sporen structuren. Hoe en waar zat de vondst in de grond. Deze tekeningen zijn erg gewild door de wetenschap. Deze kunnen een mooie verrijking zijn op de objecten zelf om de onderlinge relaties tussen de vondsten beter aan te geven.
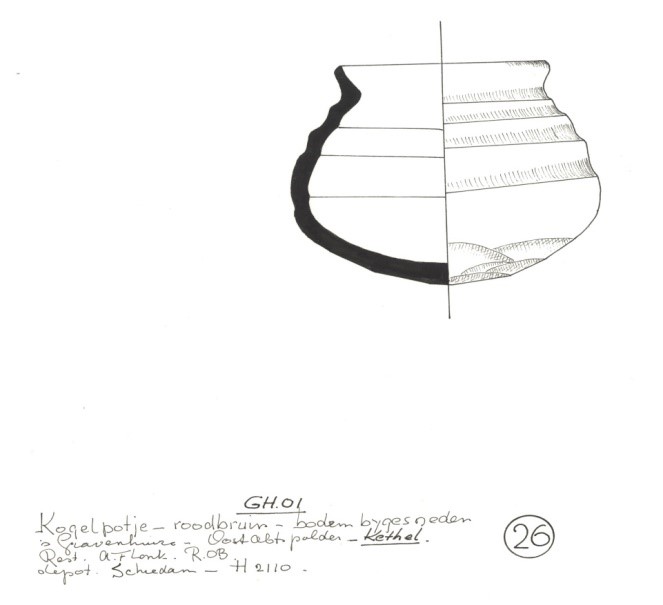
Objecttekeningen
Wat we ook tegenkomen tussen de documentatie zijn objecttekeningen. Specifieke gevonden objecten zijn dan getekend waardoor de details die via een foto minder zichtbaar zijn beter worden uitgelicht. Vaak samen met een korte omschrijving van het voorwerp. Dit geeft extra informatie over een object naast de foto en een eventuele 3D foto.
Beeldmateriaal
Daarnaast is er veel beeldmateriaal dat gemaakt is tijdens de opgravingen. Voornamelijk foto’s van de sleuven om de situatie vast te leggen, maar ook “actiefoto’s” waarbij de archeologen aan het werk zijn.

Dagrapporten
Een andere bron die te vinden is zijn logboeken. Hierin wordt per dag bijgehouden wat er allemaal gebeurde tijdens de opgraving. Wie waren er aan het werk en wat is er gevonden.
Verrijking en ontsluiting
In veel gevallen is het echter onbekend of de bewuste file bijvoorbeeld een tekening is, of een foto. Daarom is machine learning toegepast om tekst uit gescande documenten te halen en de files te schikken op basis van kleur signaturen. De verkregen informatie is gebruikt voor het toekennen van labels. Zo hebben tekeningen als kenmerk tekening meegekregen. Dit is bijvoorbeeld ook gedaan bij veelvoorkomende formulieren. Dit kan helpen om nog beter te bepalen wat het is of bijvoorbeeld selecties te maken. Deze labels zijn als metadata in een aparte folder “metadata” te vinden.
De data zijn opgeslagen op een Azure storage account. Voor het downloaden van de data zijn twee dingen nodig. Ten eerste een sleutel, te verkrijgen op aanvraag via tom [at] openstate.eu en ten tweede de Microsoft Azure storage explorer.
Hoe te gebruiken:
Ga naar https://azure.microsoft.com/nl-nl/features/storage-explorer/, download de storage explorer geschikt voor jouw platform. Klik met rechtermuisknop op “Storage Accounts” zichtbaar in de linker kantlijn en klik “Connect to Azure storage..”. Kies voor “Use a connection string or a shared access signature URI” en klik op “Next”. Kies voor “Use a SAS URI” en plak de beschikbaar gestelde key in het URI venster. Klik op connect en de verbinding komt tot stand.


